面向網絡數據的農產品價格信息資源管理與分析
本文是一篇信息系統與信息資源管理論文,本文著眼于利用網絡數據來管理和分析農產品價格信息資源。在未來的發展中,該領域有以下幾個值得關注的展望方向,一是數據質量與數據標準化:網絡數據的質量和標準化是農產品價格信息管理與分析的基礎。
1緒論
1.1研究背景和動機
農產品的價格信息對于農業生產者、供應鏈參與者和政策制定者來說至關重要。了解農產品的價格趨勢和波動可以幫助農民做出種植決策、優化生產計劃和銷售策略。對供應鏈參與者來說,準確的農產品價格信息可以幫助他們進行庫存管理、采購決策和價格定價。對政策制定者來說,農產品價格信息可以幫助他們制定農業相關政策,促進農業發展和食品安全。
傳統上,農產品價格信息主要通過市場調研、農產品交易市場和政府統計機構的報告來收集和管理。然而,這種傳統方法存在一些局限性,如數據獲取困難、時效性不高和覆蓋范圍有限。隨著互聯網和社交媒體的普及,越來越多的農產品價格信息開始以網絡數據的形式出現。這些網絡數據包括農產品價格的實時報價、交易信息、評論和用戶反饋等,具有大量、多樣化和實時更新的特點。
所以,利用網絡數據來管理和分析農產品價格信息具有重要的研究意義和實際應用價值。通過有效地收集、清洗和管理網絡數據,可以建立一種新的農產品價格信息資源管理模式。同時,利用數據分析和挖掘技術,可以從網絡數據中挖掘出有關農產品價格的趨勢、規律和關聯性,為農業生產者、供應鏈參與者和政策制定者提供更準確和實用的決策支持。因此,本研究旨在探索面向網絡數據的農產品價格信息資源管理與分析方法,以提高農產品價格信息收集、管理和利用的效率和準確性,為農業產業鏈的參與者提供更好的決策支持。
.........................
1.2研究目的和意義
本文提出了一種針對網絡數據的農產品價格信息資源管理方法。通過對網絡文本數據進行去重、結構化處理和清理,建立了面向網絡數據的農產品價格數據倉庫,運用Neo4j圖數據庫為農產品價格信息的存儲、檢索和分析提供了有效的解決方案。這對于信息資源管理領域的數據管理理論和方法的發展具有重要意義。研究中的數據預處理方法,特別是對一詞多形、一詞多義和非正式詞語的清理,有助于提高農產品價格信息的準確性和一致性。同時,建立統一的信息管理系統,為信息的組織和檢索提供了規范和便利。
研究中開發的數據獲取、篩選和集成系統,以及對外部信息的快速獲取和分類入庫,使得農產品價格信息可以及時得到更新和分析。這為農業經濟信息分析和決策支持提供了重要的數據基礎。在信息資源管理學科中,對于數據分析和決策支持的研究,該研究提供了一個實際應用的案例。
...........................
2數據和技術選擇
2.1數據選擇原則
(1)數據可靠性:選擇來自可靠和權威的數據源,如政府機構、農業部門、農產品交易平臺等。這些數據源通常具有嚴格的數據采集和驗證機制,能夠提供高質量和可信賴的農產品價格信息。
(2)數據覆蓋范圍:選擇涵蓋廣泛的數據源,包括不同地區、不同農產品以及不同市場的價格信息。這樣可以獲得全面和多樣化的農產品價格數據,更好地反映市場情況和價格變動趨勢。
(3)數據更新頻率:選擇具有較高數據更新頻率的數據源,以確保獲取到及時的農產品價格信息。農產品價格可能會隨著季節、天氣和市場需求等因素發生變化,因此需要定期更新數據以保持準確性和實時性。
(4)數據格式和結構:選擇提供結構化和標準格式數據的數據源。這樣可以方便數據的整合和處理,并能夠與知識圖譜和圖數據庫等技術相集成,實現更高效的數據管理和分析。
(5)數據獲取成本:考慮數據獲取的成本和可行性。有些數據源可能需要付費或需要特定的許可或合作關系才能獲取,因此需要綜合考慮獲取數據的成本與數據的價值。
綜合考慮上述原則,選擇合適的數據源是確保農產品價格信息資源管理與分析的有效性和可靠性的關鍵。同時,需要注意保護數據隱私和遵守相關法律法規,確保數據的合法使用和安全性。
.............................
2.2數據爬取技術
2.2.1基本概念
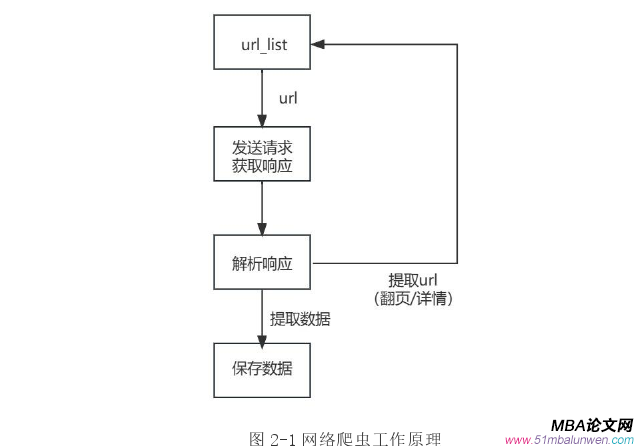
網絡爬取(Web crawling)是一種自動化獲取互聯網上信息的技術。其工作原理是選擇一個或多個初始網頁作為爬取的起點,使用HTTP請求獲取網頁的源代碼,對下載的網頁進行解析,提取其中的結構化數據,例如HTML頁面中的標簽、屬性和文本內容。從解析后的網頁中提取其他頁面的鏈接,這些鏈接可以是內部鏈接(指向同一網站的其他頁面)或外部鏈接(指向其他網站的頁面)。根據一定的策略和算法,選擇下一個要訪問的鏈接,并重復前面的步驟。將提取的數據保存在適當的格式(如數據庫、文本文件或其他數據存儲方式)中,以便后續的分析和應用。
信息系統與信息資源管理論文怎么寫
..............................
3農產品價格信息知識圖譜構建與存儲.........................20
3.1數據來源.........................................20
3.2網絡信息爬取....................................20
3.3數據預處理.......................................22
4農產品價格信息分析與預測..............................34
4.1數據集與預處理.......................................34
4.2超參數設置與模型訓練..............................37
5總結與展望...................................44
5.1總結.....................................44
5.1.1關于農產品價格信息知識圖譜與搜索系統......................44
5.1.2關于農產品價格信息分析與預測模型.....................................44
4農產品價格信息分析與預測
4.1數據集與預處理
該研究的數據來源于貴州省農經網,涵蓋了2020年8月到2023年6月期間的大蔥價格數據。研究選擇了銷售大蔥的30個市場的價格數據作為本文的數據集。為了進行模型訓練和驗證,將數據集按照時間順序劃分為80%的訓練數據集和20%的驗證數據集。
在數據預處理階段,首先需要進行空缺值插值和歸一化兩個關鍵步驟。由于市場價格監測數據受多種因素的影響,導致數據的連續性出現斷點。為了填補這些缺失值,采用了三次樣條插值法進行線性插值補全。這種方法能夠生成與價格監測數據趨勢相符的曲線,更好地反映價格數據的特征。接著,根據插值后的曲線,對缺失值進行處理,以便后續模型的訓練和預測。另外,為了提高數據的一致性和可比性,對數據進行了歸一化處理,將其轉換到統一的尺度范圍。
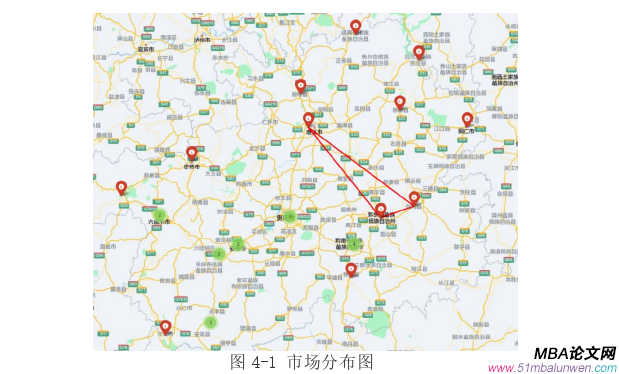
此外,市場分布圖展示了貴州省銷售大蔥的30個市場的分布情況,并指出距離越近,市場之間的影響越強,距離越遠,市場之間的影響越弱。這一觀察強調了市場之間的空間關系和相互影響的重要性,為后續建模過程提供了有價值的參考。
信息系統與信息資源管理論文參考
..........................
5總結與展望
5.1總結
5.1.1關于農產品價格信息知識圖譜與搜索系統
本系統的研究工作主要實現了貴州農產品價格信息數據的獲取與處理,構建了領域知識圖譜,并使用Neo4j進行存儲,同時開發了貴州農產品價格信息知識搜索系統。然而,在實際應用中仍存在一些問題需要進一步探究和解決,并且還有許多工作需要完成。
目前構建的知識圖譜仍需進一步完善,其中數據量也需要擴充,以提高系統的知識覆蓋面和準確性。此外,實體識別的類型相對較為有限,需要進行進一步的擴展,以識別更多相關實體,滿足更廣泛的用戶需求。
為了提高應用效果和用戶體驗,還需要進一步研究和開發工作。例如,優化數據獲取和處理流程,改進實體識別算法,提升系統的準確性和響應速度。同時,還可以考慮引入自然語言處理技術,實現更智能的查詢解析和語義理解,以提供更精準的查詢結果。
總之,盡管已經取得了一定的成果,但在實際應用中仍然面臨挑戰和改進的空間。進一步的研究和開發工作將有助于完善系統功能,提高應用效果,并為用戶提供更好的體驗。
參考文獻(略)

